
Dữ liệu lớn là gì?
Nói một cách đại thể thì big data là các tập dữ liệu rất lớn và/hoặc rất phức tạp mà những phương pháp hiện tại của CNTT chưa phân tích và xử lý tốt được chúng.
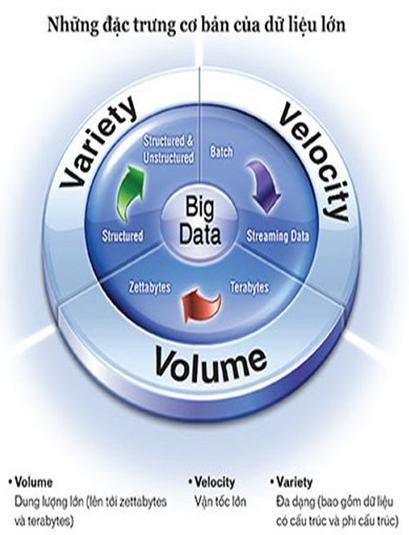
Tên gọi dữ liệu lớn khiến đa số chúng ta chỉ hình dung tính chất lớn mà không hình dung về tính phức tạp, nhưng hai tính chất này ở dữ liệu lớn luôn đi cùng nhau, trong đó tính chất "phức tạp" còn đặc trưng và thách thức hơn vấn đề về độ lớn của dữ liệu. Ta có thể tạm hình dung về điều này qua định nghĩa của IBM về dữ liệu lớn với ba chữ V: Variety, Velocity và Volume. Chữ V đầu tiên chỉ sự đa dạng, sự liên kết chằng chịt của dữ liệu với nhiều cấu trúc khác nhau, từ dữ liệu quan hệ, đến dữ liệu không cấu trúc như các văn bản thô… Chữ V thứ hai chỉ tính chất chuyển động liên tục của dòng dữ liệu rất lớn cần xử lý, khác với cách truyền thống ta thu nhận và xử lý dữ liệu theo từng mẻ (batch). Chữ V thứ ba chỉ độ lớn của dữ liệu ở mức terabytes (1012), rồi petabytes (1015 bytes), và cả zetabytes (1018 bytes).
Ai cũng biết dữ liệu là nguồn chứa hầu hết mọi thông tin của con người, nhưng những thông tin này không lồ lộ ra cho ta dùng ngay mà ta chỉ có thể tìm ra chúng khi phân tích (xử lý) được dữ liệu, nhưng việc xử lý dữ liệu lớn là một vấn đề khó, và hiện nay con người chưa có cách làm được tốt việc này.
Dữ liệu lớn từ đâu ra?
Việc lượng dữ liệu lớn đang ngày càng rất nhiều quanh ta là một hiện thực khách quan. Dữ liệu lớn có ở rất nhiều tổ chức, nhiều hoạt động xã hội, kinh doanh, khoa học và tiềm ẩn nhiều giá trị to lớn. Nhưng dữ liệu lớn ấy đến từ đâu?
Chúng đến từ rất nhiều nguồn và ba nguồn chính là: (1) Các phương tiện truyền thông xã hội, như mỗi ngày trên toàn thế giới có 230 triệu mẩu tin trao đổi trên các twitters, có 2,7 tỷ ý kiến trao đổi trên các facebooks, và số video mỗi ngày đưa lên Youtube cần đến 86.400 giờ để xem hết; (2) Các máy móc thu nhận dữ liệu, các thiết bị công nghiệp, các cảm biến (sensors), các dụng cụ giám sát... như máy gia tốc hạt lớn của CERN (tổ chức nghiên cứu nguyên tử châu Âu) tạo ra 40 terabytes dữ liệu mỗi giây… (3) Giao dịch kinh doanh, từ số liệu giá cả sản phẩm, thanh toán, dữ liệu chế tạo và phân bố... như số sản phẩm Amazon.com bán trong Quý 3 năm 2011 có giá trị 10 tỷ USD, như dãy các nhà hàng Domino bán pizza trên toàn nước Mỹ đạt 1 triệu khách mỗi ngày...
Dữ liệu lớn và lợi ích chiến lược của quốc gia
Ngày 29 tháng 3 năm 2012, Văn phòng chính sách khoa học và công nghệ của Mỹ thuộc Văn phòng điều hành của Tổng thống Mỹ đã công bố 84 chương trình về dữ liệu lớn thuộc 6 Bộ của Chính quyền Liên bang. Những chương trình này đề cập đến thách thức và cơ hội của cuộc cách mạng dữ liệu lớn và xem việc tìm lời giải cho vấn đề dữ liệu lớn là sứ mệnh của các cơ quan chính phủ cũng như của việc cách tân và khám phá khoa học.
Ở Bộ Quốc phòng Mỹ, một kinh phí 250 triệu USD hằng năm được dành cho 8 chương trình của "sự đánh cuộc lớn với dữ liệu lớn", nhằm khai thác và sử dụng dữ liệu lớn bằng những cách mới để giúp các hệ thống tự động ra quyết định, nâng cao khả năng máy tự nhận biết và đánh giá các tình huống phức tạp để hỗ trợ tác chiến. Chẳng hạn chương trình CINDER (Cyber-Insider Threat) nhằm phát triển các phương pháp mới để phát hiện các hoạt động gián điệp trên mạng máy tính quân sự. Một cách nhằm phát hiện các hoạt động gián điệp ẩn giấu là CINDER sẽ áp dụng rất nhiều mô hình hoạt động của đối phương để điều chỉnh các hoạt động trên mạng máy tính nội bộ. Chương trình đọc máy (machine reading) nhằm ứng dụng trí tuệ nhân tạo để phát triển các hệ thống có thể "hiểu" và định được nghĩa của văn bản thay cho con người làm việc này vốn rất tốn kém và chậm chạp.
Còn tại Bộ Năng lượng Mỹ, nhiều chương trình được xây dựng nhằm tạo ra khả năng dẫn đầu về các kỹ thuật quản lý, hiển thị và phân tích dữ liệu lớn. Chẳng hạn chương trình "Toán học phục vụ phân tích dữ liệu cỡ peta" đề cập các thách thức toán học nhằm thấu hiểu được các tập dữ liệu khổng lồ, hoặc tìm ra các thuộc tính cốt lõi từ dữ liệu và hiểu được mối quan hệ giữa các thuộc tính này. Đây cũng là mục tiêu của nhiều chương trình do Quỹ khoa học quốc gia (NSF) tài trợ cho nhiều đại học và viện nghiên cứu nhằm xây dựng các kỹ thuật và công nghệ nền của dữ liệu lớn.
Ngoài ra có nhiều chương trình ở các lĩnh vực khác như an ninh quốc gia (từ phân tích và dự báo các thảm họa thiên nhiên đến các vụ tấn công khủng bố), dịch vụ cho sức khoẻ con người (ngăn chặn và điều khiển dịch bệnh, chế tạo thuốc...), nghiên cứu không gian, nghiên cứu trái đất... tất cả đều liên quan đến dữ liệu lớn.
Các quốc gia khác cũng có những chương trình khoa học về dữ liệu lớn, ví dụ như chương trình FIRST của Nhật (the Funding Program for World-leading Innovative R&D on Science and Technology) nhằm thúc đẩy các nghiên cứu cách tân và dẫn đầu trong cuộc cạnh tranh quốc tế trung và dài hạn, có một phần lớn gồm gần 50 đề tài nhánh về phát triển các phương pháp khai thác cơ sở dữ liệu rất lớn cho phép thực hiện và đánh giá các dịch vụ xã hội có tính chiến lược. Ngày 2 tháng 6 năm 2012, giám đốc NSF Subra Suresh của Mỹ và Bộ trưởng Bộ Giáo dục, văn hóa, thể thao, khoa học và công nghệ (MEXT) Hirofumi Hirano của Nhật đã ký một thỏa thuận hợp tác nghiên cứu về dữ liệu lớn và thảm họa thiên nhiên.
Dữ liệu lớn và công nghiệp
Nhưng chính các doanh nghiệp và các công ty công nghiệp là những nơi đang quan tâm nhiều hơn cả đến dữ liệu lớn, coi đây là một trong những yếu tố có ảnh hưởng quan trọng tới tình hình kinh doanh và phát triển của doanh nghiệp trong tương lai. Chúng ta đã nghe nói về các nhà khoa học đang dùng siêu máy tính để phân tích những lượng dữ liệu khổng lồ trong nghiên cứu. Hiện nay, sau những bước đi tiên phong của khoa học, không chỉ giới khoa học mà những người làm kinh doanh thông minh (business intelligence) đã có thể truy nhập tới các nguồn dữ liệu lớn, và các doanh nghiệp đã bắt đầu có thể khai thác dữ liệu lớn.
Để hiểu được tại sao nhiều công ty quan tâm tới dữ liệu lớn, cần biết xu hướng là một số công ty lớn rất nổi tiếng về chế tạo thiết bị trong quá khứ hiện đang chuyển dần thành các công ty cung cấp dịch vụ, chẳng hạn hướng tới cung cấp phân tích kinh doanh (business analytics). Một thí dụ là IBM. Trước kia IBM chế tạo các máy chủ, máy tính để bàn, máy tính xách tay, và thiết bị cho hạ tầng cơ sở. Hiện nay IBM đã ngừng sản xuất một số loại thiết bị như máy tính xách tay (IBM ThinkPad) và thay vào đó đầu tư hàng tỷ đôla để gây dựng và nhằm đạt được vị trí dẫn đầu trong phân tích kinh doanh. IBM đã đầu tư hơn một tỷ USD dùng SPSS trong phân tích kinh doanh để giành được thị phần bán lẻ. Đối với các kinh doanh thương mại lớn IBM dùng Cognos để cung cấp toàn bộ phân tích dịch vụ.
Một ví dụ điển hình khác là, Google, một đại gia về dữ liệu lớn. Mấy ai không từng kinh ngạc sao Google có thể tìm kiếm rất nhanh thông tin trên không gian bao la các trang web chỉ với mấy từ khóa ta đưa vào. Có thể coi Google là người tiên phong trong quản lý và xử lý các lượng dữ liệu khổng lồ. Hiện nay, trên con đường làm chủ dữ liệu lớn, Google đang tiếp tục hoàn thiện công nghệ riêng của mình để phân tích nhanh và tương tác với những lượng dữ liệu khổng lồ: Quản trị dữ liệu bởi Cloud Storage và phân tích dữ liệu bởi BigQuery (nối với công cụ hiển thị của công ty Tableau).
Theo số liệu ngày 15/10/2012 của các tổ chức nghiên cứu thị trường toàn cầu Forbes và Gartner, đầu tư của các doanh nghiệp cho dữ liệu lớn chiếm 88% trên tổng đầu tư. Các công ty đầu tư cho dữ liệu lớn vì họ nhìn thấy việc làm chủ được dữ liệu lớn sẽ cho phép giải quyết nhiều vấn đề phức tạp trước kia không thể làm được hoặc có thể tạo ra các quyết định và hành động tốt hơn. Và điều này cho phép họ có được các ưu thế cạnh tranh, điều cốt tử trong bối cảnh toàn cầu hiện nay. Ngoài ra, làm chủ dữ liệu lớn từ các mạng xã hội cho phép thấu hiểu các hành vi phức tạp của xã hội con người, và nhiều hy vọng ở những đột phá trong khoa học.
Theo dự đoán của Gartner, trong 5 năm 2012-2017 thế giới sẽ đầu tư 232 tỷ USD cho dữ liệu lớn. Tuy nhiên, Gartner cũng dự đoán cho đến cuối 2015, 85% công ty trong bảng xếp hạng 500 công ty lớn nhất Hoa Kỳ (Fortune 500) sẽ thất bại trong việc khai thác dữ liệu lớn. Đơn giản vì các phương pháp và kỹ thuật cho dữ liệu lớn trong ba năm tới chưa đáp ứng được nhu cầu sử dụng, và nhiều phương pháp mới đang được hy vọng sẽ sớm xuất hiện.
Chìa khóa của dữ liệu lớn
Vậy đâu là chìa khóa khoa học và công nghệ của dữ liệu lớn?
Hình bên giới thiệu một mô hình tổng quát về khai thác dữ liệu lớn. Mặc dù đang còn phát triển, ba chìa khóa chính của khai thác dữ liệu lớn luôn được xem là: (1) Quản trị dữ liệu, tức lưu trữ, bảo trì và truy nhập các nguồn dữ liệu lớn; (2) Phân tích dữ liệu, tức tìm cách hiểu được dữ liệu và tìm ra các thông tin hoặc tri thức quý báu từ dữ liệu; (3) Hiển thị (visualization) dữ liệu và kết quả phân tích dữ liệu.
Phát triển công cụ quản trị dữ liệu lớn, nghiên cứu về các kỹ thuật hiển thị dữ liệu lớn, về mối quan hệ phức tạp trong chúng, là những thách thức không nhỏ, nhưng thách thức chính của dữ liệu lớn là các phương pháp phân tích dữ liệu, trong đó chủ yếu là các phương pháp của hai lĩnh vực học máy và khai phá dữ liệu.
Học máy (machine learning) là một lĩnh vực của CNTT nhằm làm cho máy tính có một số khả năng học tập của con người, chủ yếu là học để khám phá. Cốt lõi của việc tạo ra khả năng tự học này của máy là việc phân tích các tập dữ liệu để phát hiện ra các quy luật, các mẫu dạng, các mô hình. Lĩnh vực học máy đã phát triển quãng 40 năm, và đặc biệt bùng nổ trong vòng hơn mười năm qua. Kết hợp ngày càng nhiều hơn với toán học, đặc biệt với hai ngành thống kê và tối ưu, các phương pháp học máy càng mạnh hơn khi phân tích các dữ liệu phức tạp.
Khai phá dữ liệu (data mining) là một lĩnh vực phát triển trong khoảng gần hai mươi năm qua, tập trung vào việc đưa các phương pháp học máy vào phân tích, khai thác các tập dữ liệu lớn có trong các lĩnh vực khác nhau. Những hướng nghiên cứu gần đây về mô hình làm thưa, giảm số chiều, mô hình đồ thị xác suất... trong hai lĩnh vực học máy và khai phá dữ liệu chính là những hướng đi tới các phương pháp phân tích dữ liệu lớn trong những năm tới đây.
Chúng ta có cần quan tâm đến dữ liệu lớn?
Đây là câu hỏi nhiều người đã đặt ra trong các seminar khi chúng tôi giới thiệu về dữ liệu lớn ở Hà Nội và thành phố Hồ Chí Minh. Số đông người hỏi đều nghĩ là Việt Nam ta chưa có những tập dữ liệu lớn.
Câu trả lời của chúng tôi là cần lo ngay cho dữ liệu lớn, vì rất nhiều lý do. Thật ra các lĩnh vực truyền thông, thương mại, giao thông, các mạng xã hội, v.v ở trong nước cũng đã có những tập dữ liệu lớn, nhất là khi xét theo khía cạnh độ phức tạp. Ngay trong nền kinh tế nội địa, ai phân tích được những nguồn dữ liệu lớn đều có cơ hội tìm ra những lợi thế kinh doanh. Về giao thông ở các thành phố lớn như Hồ Chí Minh hay Hà Nội, nếu đã đặt được nhiều bộ cảm ứng ở rất nhiều điểm và lượng dữ liệu thu được cũng có thể coi là khổng lồ và phức tạp. Muốn giải quyết bài toán giao thông đô thị ta không thể không xem xét dựa trên dữ liệu lớn này. Cũng tương tự như vậy, nếu muốn giải bài toán dự đoán lũ lụt miền Trung, ta phải thu được rất nhiều dữ liệu phức tạp về dòng chảy các sông ngòi, về lượng mưa, v.v. Ở đây, dễ dàng thấy mối liên quan chặt chẽ giữa dữ liệu lớn với khoa học và kỹ thuật tính toán 2.
Đứng ngoài xu thế chung của thế giới sẽ tất yếu khiến chúng ta bị lúng túng khi bắt buộc phải đối đầu với dữ liệu lớn. Đột phá về phương pháp phân tích dữ liệu lớn cũng có thể mở ra cho ta những con đường sản xuất kinh doanh trong ngành CNTT ở trong và ngoài nước. Và chắc chắn dữ liệu lớn đang là vấn đề được quan tâm bởi các công ty CNTT hàng đầu trong nước.